IBRNet: Learning Multi-View Image-Based Rendering (CVPR2021)
以前紹介したNeRFは,Radiance Fieldを学習することで高品質な自由視点映像を生成することが可能だが,Radiance Fieldの学習には多くの計算コストを必要とするという問題がある.そのため,解像度を上げることや大規模なシーンへの適用が難しいというスケーラビリティの問題があった.IBRNetはこのようなNeRFのスケーラビリティの問題を解決するためのアルゴリズムとなっている.
IBRNet: Learning Multi-View Image-Based Rendering
https://ibrnet.github.io/
IBRNetはNeRFなどの多くの学習ベースの自由視点画像生成アルゴリズムで必要となる対象シーン毎の学習が不要なアルゴリズムである.NeRFでは対象となるシーンの学習に十数時間から数日の時間を要していたのに対して,IBRNetでは即座に自由視点画像の生成を行うことができる.(ただし,Rendering部分はほぼ同じなので,リアルタイム処理は実現できないと思う)
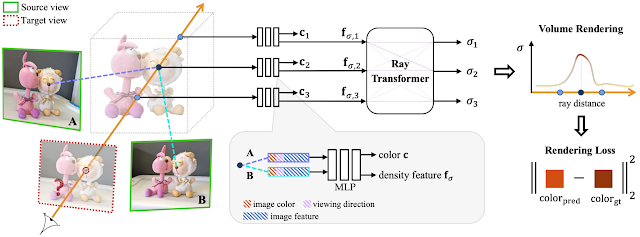
基本的なアイデアは,Classicalな自由視点画像生成アルゴリズムであるImage-based renderingのように生成する視点の周辺で撮影されている画像群のみを用いて新視点画像を生成するというものである.これを実現するために,近傍の視点画像のブレンディングによってVolume Renderingに必要なRGB-σの情報を生成するネットワークを構築するというものである.ネットワークの概要は以下のようになっている.
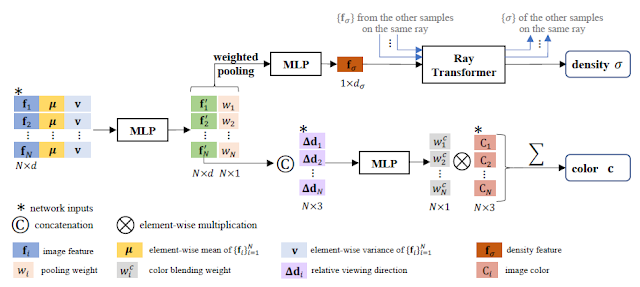
各視点画像のカメラパラメータ(内部,外部)は既知で,各視点画像はRGBの色情報の他にU-Net上のネットワークを用いて抽出されたDense Feature fを持っている.IBRNetでは,対象となる視点から光線を飛ばし,この光線上をサンプルした点の位置,方向に対応するRGB-σの値を出力する.RGB-σの値は,まず,サンプルした点を近傍の視点画像上へ投影し対応する画像特徴を算出する.各画像特徴は局所的な特徴を表現しているが,自由視点画像を生成するためには大局的な特徴も重要であるため,画像特徴の各要素の平均μと分散vを算出しネットワークの入力にする.これにより局所的,大局的双方を考慮した特徴を抽出する.その後,この特徴をカラーの情報を算出するネットワークとDensity σを算出するネットワークにそれぞれ入力する.
Density σを算出するネットワークでは,光線上の他のサンプル点の情報も考慮するためのRay Transformerを導入している.Ray Transformerにはカメラの視点からの距離に応じてサンプル点をソートし入力する.これにより,物体の境界部分(オクルーディングバウンダリ)においてアーティファクトが生じるのを防ぐことが出来るようになるらしい.
一方,色情報を生成するネットワークでは,対象となる視点の方向と近傍視点画像の撮影方向の差Δdに基づいてブレンディングの重みを算出するネットワークを学習する.これにより,新視点からの見た目に近い画像が優先的に利用されるようになる.
IBRNetでは,シーン毎の学習をせずにNeRFと同様にRadiance Fieldを取得することが可能だが,対象となるシーンに対してFine Tuningすることもできる.学習無しでも,NeRFに匹敵するような品質の画像を生成することが出来るが,Fine TuningすることによりNeRFよりも高品質な画像を生成することが可能になる.以下の結果画像でOursが対象となるシーンでの学習無し,OursftがFine Tuningした結果となっている.Fine Tuningすることで,より詳細な画像を生成することが出来ている.


コメント
コメントを投稿